Mind the delay in Azure Functions outputs
When working with Azure Functions, items added using queue and table bindings are handled differently, and you should keep that in mind.
Computing without overhead Azure Functions
Using Azure Functions developers can easily implement computing logic. With virtually no startup overhead, you can create a new Function App in your Azure subscription and build your first Function in just a few minutes. As the load increases your Function will scale out providing you with efficient data processing at minimum costs.
Azure Functions triggers and bindings
Azure Functions can be triggered in a number of ways, such as by an HTTP request or a queue message, what makes them suitable for a variety of scenarios. Azure Functions come with a preconfigured set of triggers that you can choose from when building your Function.
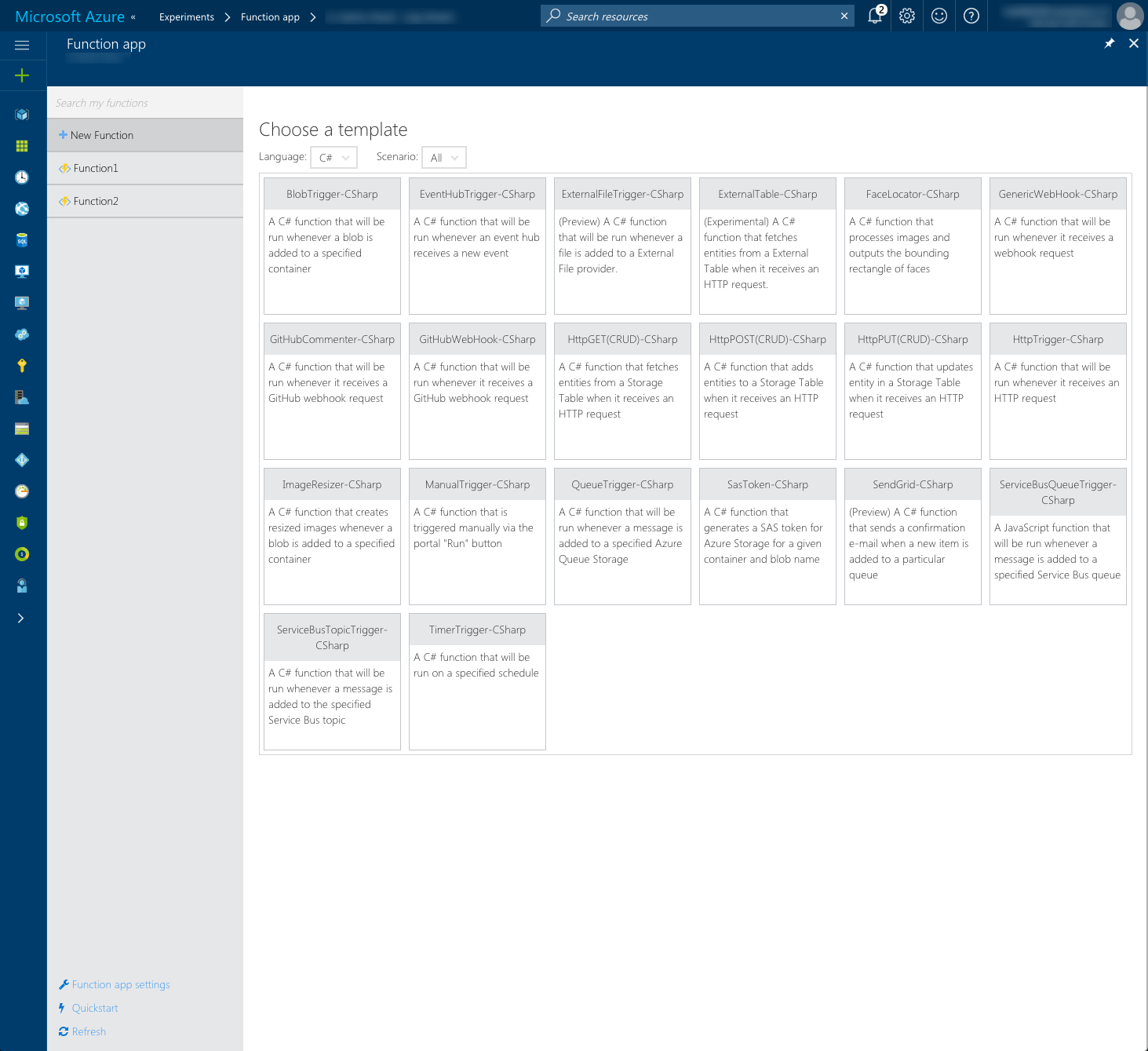
As Functions are likely to process data, it’s extremely easy to connect a Function to a database or Azure Storage. Through Function’s configuration you can easily add outputs (sometimes referred to as bindings) that represent data stores to which the particular Function should be able to write. Similarly to triggers, there are a number of ready-to-use output types that you can choose from.

In some cases the trigger of your Azure Function doesn’t provide it with all the necessary information to execute. May it be for security or performance reasons you might build a Function in a way that the trigger contains a pointer to another location where all the necessary information required by the Function is stored. In such cases you can define additional inputs in your Function to connect it to data stores from which it should be able to read data. Similarly to outputs, there a number of input types that you can choose from when building your Azure Function.
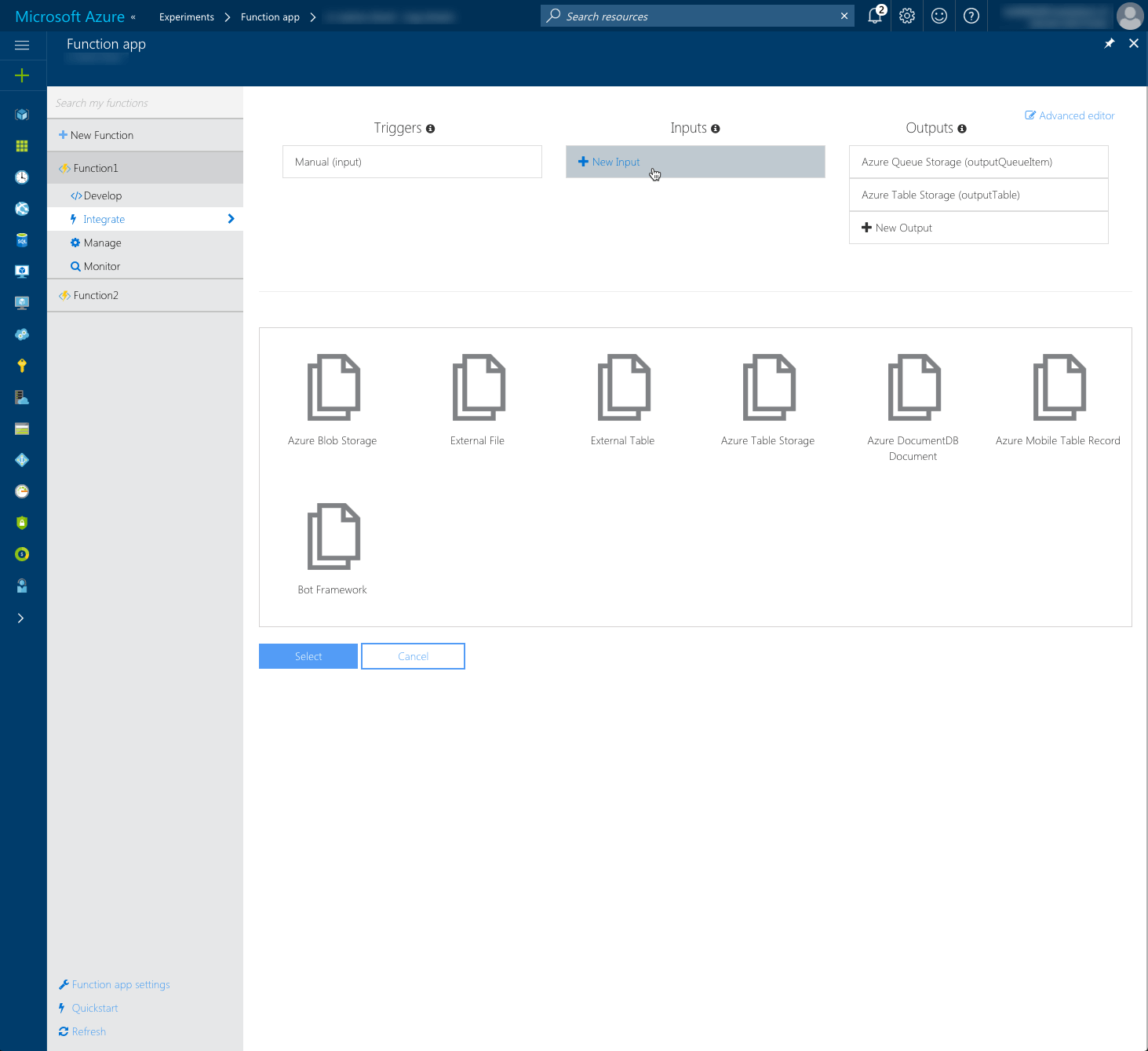
Connecting Azure Functions to data stores through triggers, inputs and outputs/bindings makes it extremely easy for developers to work with data. Every trigger, input and output is expressed by a variable passed as an argument into the Function. Using that variable developers can directly get to the data without worrying about setting up connections in code.
Azure Functions abstract away connecting to data stores but it all comes with a price.
Mind the gap
When working with Azure Functions outputs the way Azure Storage Queues and Azure Storage Tables are handled is different. Where messages passed to a queue are enqueued immediately, rows added to a table are added after the Function execution completed.
Comparing to Azure Storage Tables, Azure Storage Queues allow you to store less data. This makes it plausible for you to want to store the data that should be analyzed in a table and in the queue message include the minimal information required by the Function to retrieve the data from the table.
If you have a Function that writes to Azure Storage Queue and Azure Storage Table using its outputs, and then another Function that is triggered by the queue you might find yourself in a situation where the table row corresponding to the queue message being processed at the moment isn’t available yet.
Let’s take the following Azure Function as an example:
#r "Microsoft.WindowsAzure.Storage"
#r "Newtonsoft.Json"
using Microsoft.WindowsAzure.Storage.Table;
using Newtonsoft.Json;
using System;
public static void Run(string input, ICollector<string> outputQueueItem, ICollector<Data> outputTable, TraceWriter log) {
for (var i = 0; i < 10; i++) {
var rowKey = Guid.NewGuid().ToString();
var data = new Data {
PartitionKey = "partition1",
RowKey = rowKey,
Title = "msg" + i,
Timestamp = DateTime.Now
};
outputTable.Add(data);
var queueItem = JsonConvert.SerializeObject(new {
PartitionKey = "partition1",
RowKey = rowKey
});
outputQueueItem.Add(queueItem);
System.Threading.Thread.Sleep(500);
}
}
public class Data: TableEntity {
public string Title { get; set; }
}When executing, the Function adds 10 rows to a table. For every item it also adds a message to the queue with the pointer to the corresponding table row. Between adding items, the Function waits for 500ms to highlight the difference in how queues and tables are processed.
The Function is configured as follows:
{
"bindings": [
{
"type": "manualTrigger",
"direction": "in",
"name": "input"
},
{
"type": "queue",
"name": "outputQueueItem",
"queueName": "outqueue",
"connection": "Storage",
"direction": "out"
},
{
"type": "table",
"name": "outputTable",
"tableName": "outTable",
"connection": "Storage",
"direction": "out"
}
],
"disabled": false
}If you would run this Function you should see 10 rows added to the table:
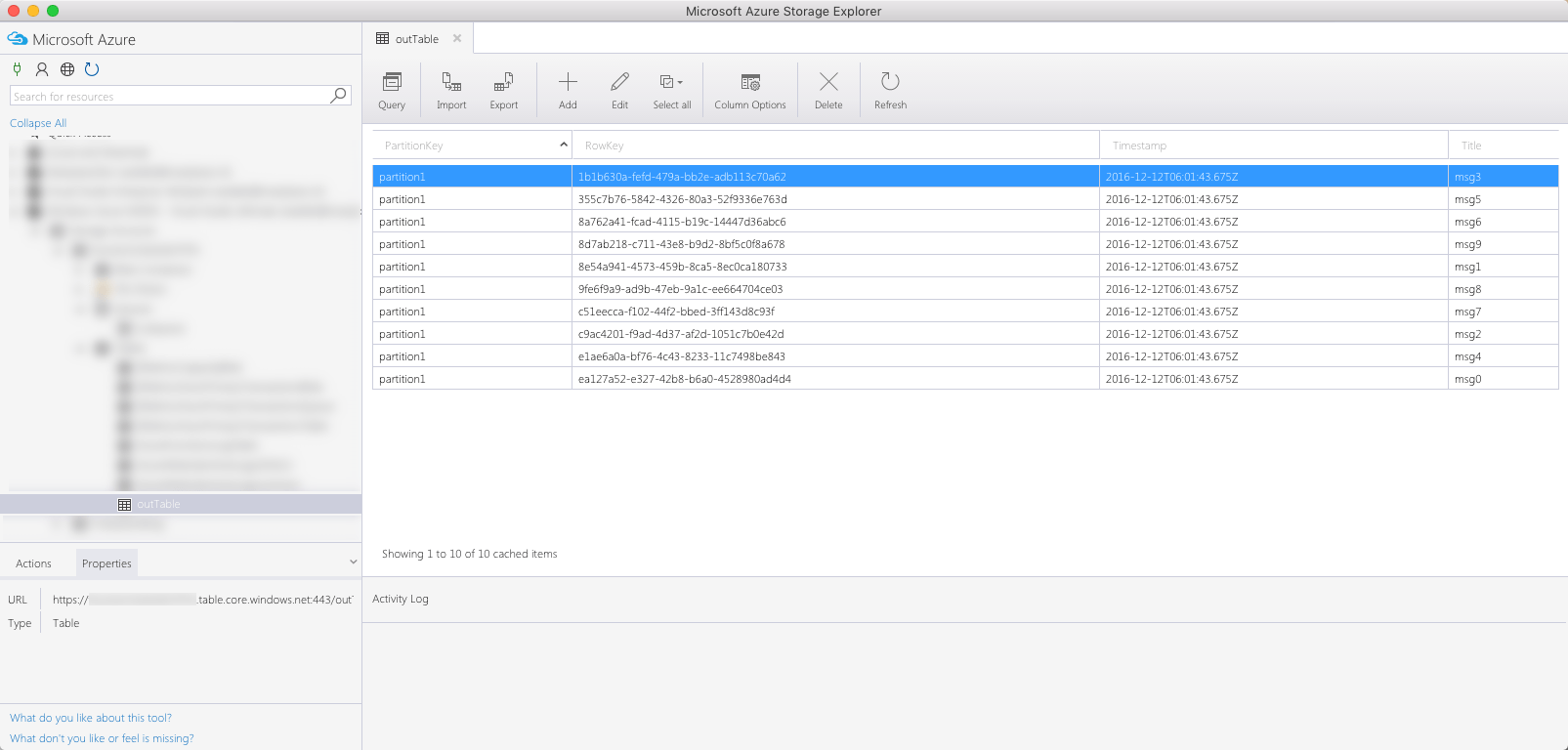
and 10 messages enqueued in the queue:
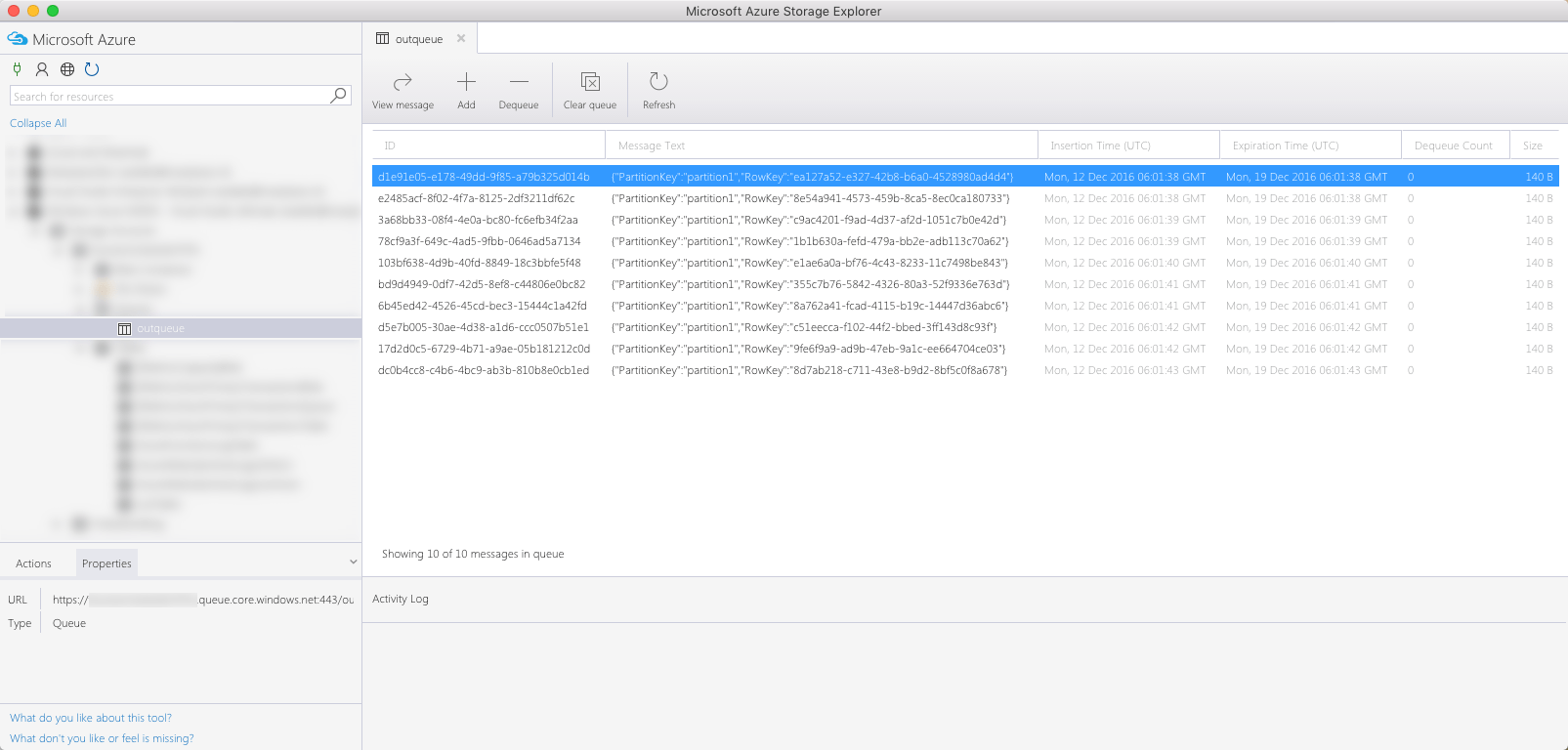
If you compare the Insertion Time of messages in the queue table with the Timestamp of rows in the table, you will see that while there are two messages enqueued every second (which corresponds to the 500ms delay in the code), all rows in the table are added at the same time time corresponding to the time of the last enqueued message!
Imagine now that you have another queue-triggered Function that would pick up messages added by the Function mentioned earlier:
#r "Microsoft.WindowsAzure.Storage"
#r "Newtonsoft.Json"
#r "System.Xml.Linq"
using Microsoft.WindowsAzure.Storage.Table;
using Newtonsoft.Json;
using System;
using System.Xml.Linq;
public static void Run(dynamic myQueueItem, IQueryable<Data> inputTable, TraceWriter log) {
string partitionKey = myQueueItem.PartitionKey.ToString();
string rowKey = myQueueItem.RowKey.ToString();
var data = inputTable.Where(o => o.PartitionKey == partitionKey && o.RowKey == rowKey).FirstOrDefault();
if (data == null) {
log.Error($"ERROR: Couldn't find data with RowKey {rowKey} and ParititionKey {partitionKey}");
return;
}
log.Info(JsonConvert.SerializeObject(data));
}
public class Data: TableEntity {
public string Title { get; set; }
}As the Function needs to retrieve the additional information from the table, it defines it as an additional input:
{
"bindings": [
{
"name": "myQueueItem",
"type": "queueTrigger",
"direction": "in",
"queueName": "outqueue",
"connection": "Storage"
},
{
"type": "table",
"name": "inputTable",
"tableName": "outTable",
"take": 50,
"connection": "Storage",
"direction": "in"
}
],
"disabled": false
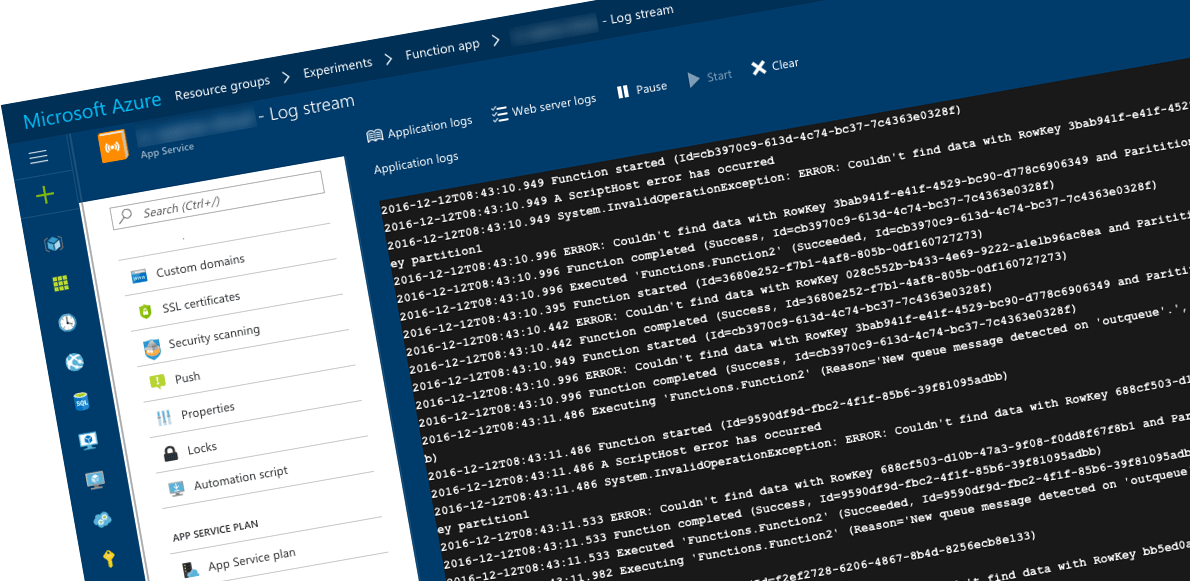
}If you would start the first Function to enqueue items and would take a look at the Log Stream you would see that every single time the second Function failed.
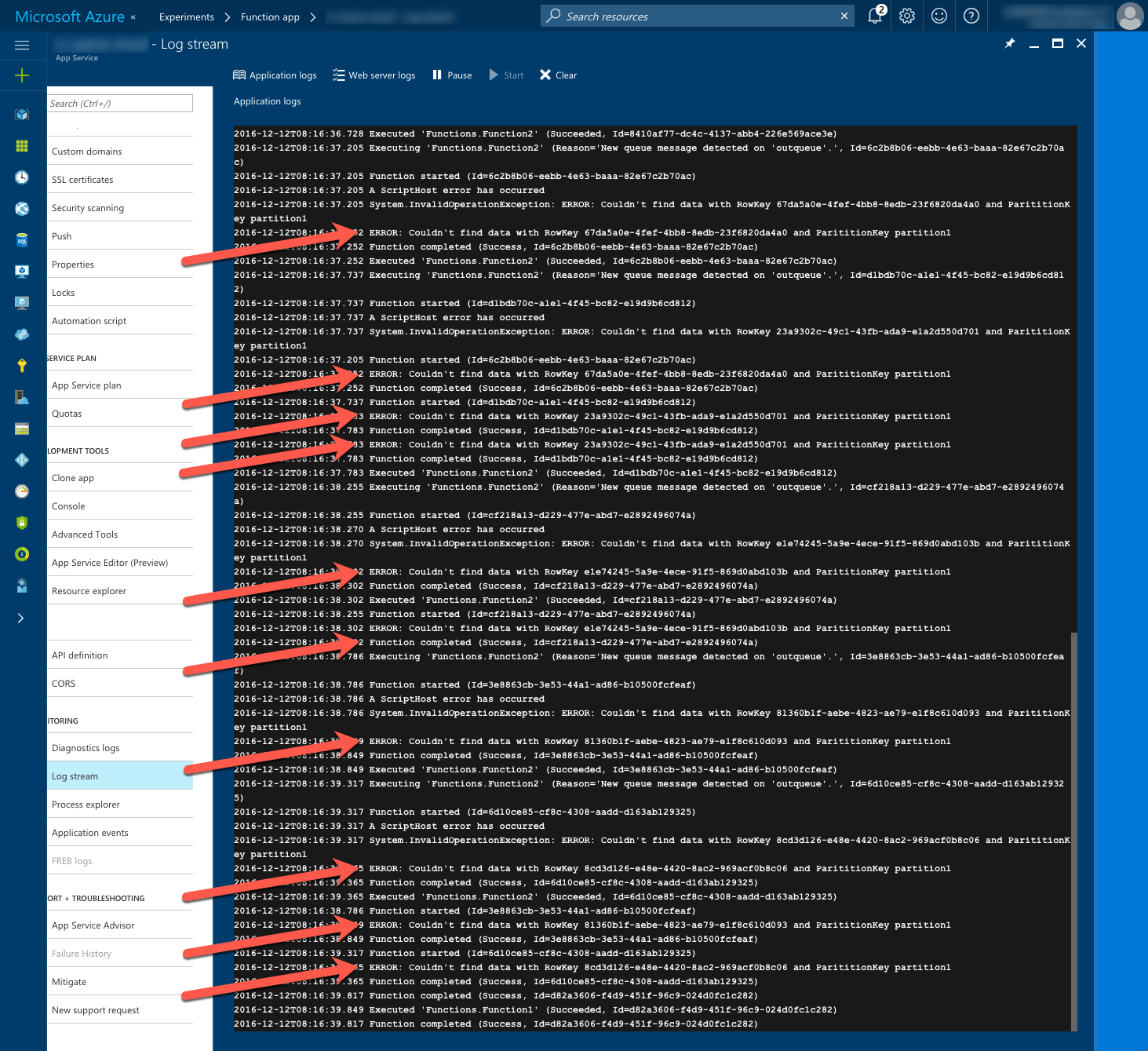
So is there anything that you can do about it?
Adding items to the table manually
One thing that you can do, to solve the issue of queue outputs being processed before table outputs, is not to use table outputs and add rows to Azure Storage Table manually instead.
So instead of:
outputTable.Add(data);you would use:
var storageAccount = CloudStorageAccount.Parse(System.Environment.GetEnvironmentVariable("Storage", EnvironmentVariableTarget.Process));
var tableClient = storageAccount.CreateCloudTableClient();
var cloudTable = tableClient.GetTableReference("outTable");
cloudTable.CreateIfNotExists();
var insertOperation = TableOperation.Insert(data);
await cloudTable.ExecuteAsync(insertOperation);While the code is obviously more complex, it allows you to control when exactly the row is added to the table. When the second Function picks up the enqueued message it can successfully retrieve the corresponding row from the table.
Summary
Using Azure Functions developers can easily implement computing logic. Through triggers, inputs and outputs developers can easily connect Functions to data stores. When working with queue outputs messages are added to the queue directly, while when using table outputs all rows are added at once after Function completed. If you want to ensure that data corresponding to the queue message is available to a queue-triggered Function, you should add data to the table manually rather than using a Function output.